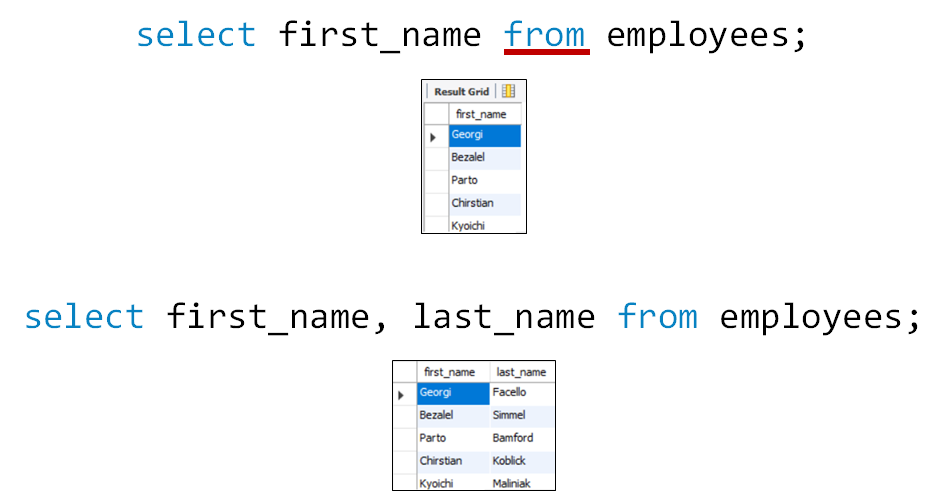
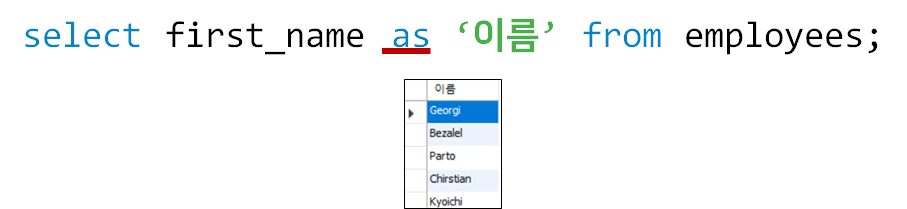
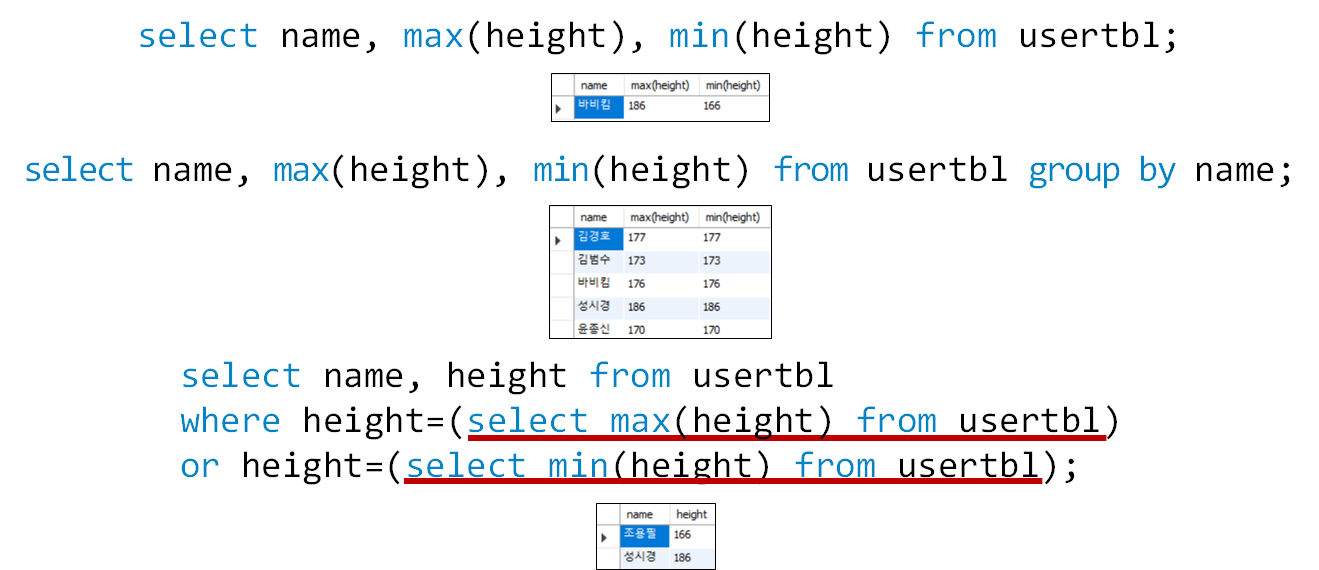
전체 텍스트 검색은 긴 문자의 텍스트 데이터를 빠르게 검색하기 위한 MySQL의 부가적인 기능이다. 전체 텍스트 검색을 사용하면 기사의 내용에 포함된 여러 단어들에 인덱스가 설정되어서 검색 시에 인덱스를 사용하여 검색 속도가 월등히 빨라진다.
전체 텍스트 인덱스는 신문기사와 같이 텍스트로 이루어진 문자열 데이터의 내용을 가지고 생성한 인덱스를 말한다.

SELECT * FROM 신문기사_테이블 WHERE 신문기사내용 '교통 사고의 증가로 인해 오늘 ----';SELECT * FROM 신문기사_테이블 WHERE 신문기사내용 LIKE '교통%';인덱스가 정렬되어 있으므로, 해당되는 내용이 인덱스를 통해서 빠르게 검색함.
SELECT * FROM 신문기사_테이블 WHERE 신문기사내용 LIKE '%교통%';
전체 테이블 검색을 하게 됨. 만약 10년치 기사에서 검색한다면 과부하가 발생하고 응답시간도 긺.
이것을 전체 텍스트 검색이 해결한다. 전체 텍스트 검색은 첫 글자 뿐 아니라 중간의 단어나 문장으로도 인덱스를 생성해 주기 때문에 이와 같은 상황에서도 인덱스(정확히는 전체 텍스트 인덱스)를 사용할 수 있어 순식간에 검색 결과를 얻을 수 있다.
전체 텍스트 인덱스는 신문기사와 같이, 텍스트로 이루어진 문자열 데이터의 내용을 가지고 생성한 인덱스를 말한다. MySQL에서 생성한 일반적인 인덱스와는 몇 가지 차이점이 있다.
- 전체 텍스트 인덱스는 InnoDB와 MylSAM 테이블만 지원한다.
- 전체 텍스트 인덱스는 char, varchar, text의 열에만 생성이 가능하다.
- 인덱스 힌트의 사용이 일부 제한된다.
- 여러 개의 열에 FULLTEXT 인덱스를 지정할 수 있다.
1. 전체 텍스트 인덱스 생성
3가지 방법:
CREATE TABLE 테이블이름(
…
열이름 데이터형식,
…,
FULLTEXT 인덱스이름 (열이름)
);CREATE TABLE 테이블이름(
…
열이름 데이터형식,
…,
);
ALTER TABLE 테이블이름
ADD FULLTEXT (열이름);CREATE TABLE 테이블이름(
…
열이름 데이터형식,
…,
);
CREATE FULLTEXT INDEX 인덱스이름
ON 테이블이름 (열이름);
2. 전체 텍스트 인덱스 삭제
ALTER TABLE 테이블이름
DROP INDEX FULLTEXT (열이름);3. 중지 단어(stopwords)
실제로 검색할 때 무시할 만한 단어들은 아예 전체 텍스트 인덱스로 생성하지 않는 편이 좋다.
|
이번 |
선거는 |
아주 |
중요한 |
행사이므로 |
모두 |
꼭 |
참여 |
바랍니다 |
‘이번’, ‘아주’, ‘모두’, ‘꼭’ 등과 같은 단어는 검색할 이유가 없으므로 제외한다. 이것이 중지 단어이다.
MySQL 5.7은 INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD 테이블에 약 36개의 중지 단어를 가지고 있다.

4. 전체 텍스트 검색을 위한 쿼리
전체 텍스트 인덱스를 생성한 후에 이를 사용하기 위한 쿼리는 일반 SELECT문의 WHERE절에 MATCH() AGAINST()를 사용하면 된다.
MATCH (col1, col2, ...) AGAINST (expr [search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}- 자연어 검색
특별히 옵션을 지정하지 않거나 IN NATURAL LANGUAGE MODE를 붙이면 자연어 검색을 한다. 자연어 검색은 단어가 정확한 것을 검색해 준다.
newspaper이라는 테이블의 article이라는 열에 전체 텍스트 인덱스가 생성되어 있다고 가정한다.
‘영화’라는 단어가 들어간 기사를 찾으려면 다음과 같이 사용한다.
SELECT * FROM newspaper
WHERE MATCH(article) AGAINST('영화');‘영화는’, ‘영화가’ 등 검색 불가.
‘영화’ 또는 ‘배우’ 두 단어 중 하나가 포함된 기사 검색.
SELECT * FROM newspaper
WHERE MATCH(article) AGAINST('영화 배우');- BOOLEAN MODE 검색
단어나 문장이 정확히 일치하지 않는 것도 검색하는 것을 의미한다.
|
+ |
검색 필수 SELECT * FROM newspaper WHERE MATCH(article) AGAINST('영화 +액션' IN BOOLEAN MODE); |
|
- |
검색 제외 SELECT * FROM newspaper WHERE MATCH(article) AGAINST('영화 -액션' IN BOOLEAN MODE); |
|
~ |
검색 부정(-보다 부드러운 방식) SELECT * FROM newspaper WHERE MATCH(article) AGAINST('영화 ~액션' IN BOOLEAN MODE); ‘영화’를 찾되 ‘액션’이 없는 열보다 ‘액션’이 있는 열이 아래 순위 |
|
* |
부분 검색 SELECT * FROM newspaper WHERE MATCH(article) AGAINST('영화*' IN BOOLEAN MODE); ‘영화를’, ‘영화가’, ‘영화는’ 등 |
|
“ |
“”안에 있는 구문과 정확히 동일한 철자의 구문 부분 검색 SELECT * FROM newspaper WHERE MATCH(article) AGAINST("재밌는 영화" IN BOOLEAN MODE); “재밌는 영화”, “재밌는 영화가” 등 “재밌는 한국 영화”, “재밌는 할리우드 영화” 불가 |
5. 실습

MySQL은 기본적으로 3글자 이상만 전체 텍스트 인덱스로 생성한다. 이러한 설정을 2글자까지 전체 텍스트 인덱스가 생성되도록 시스템 변숫값을 변경한다.





아직 인덱스를 만들지 않은 상태.

실행계획(전체 테이블 검색)

전체 텍스트 인덱스 생성.


실행계획(전체 텍스트 인덱스 검색)

‘남자’ 또는 ‘여자’가 들어간 행 검색.

‘남자’, ‘여자’ 모두 들어간 행 검색.

‘남자’가 들어간 행 중에 ‘여자’는 제외된 행 검색.

전체 텍스트 인덱스로 만들어진 단어들.

원래 있던 전체 텍스트 인덱스를 삭제하고 불필요한 중지 단어를 지정.


'MySQL' 카테고리의 다른 글
| MySQL 잠금기능 (0) | 2020.02.20 |
|---|---|
| MySQL view(뷰) (0) | 2020.02.17 |
| MySQL SELECT문 (1) | 2020.02.10 |